# Testing Guide This guide is intended to layout the general test strategy for OpenLMIS.
OpenLMIS, like many software projects, relies on testing to guide development and prevent regressions. To effect this, we’ve adopted a standard set of tools to write and execute our tests, and categorize them to understand what types of tests we have, who writes them, when they’re written, run, and where they live.
The objective of manual and automatic tests is to catch bugs as quickly as possible after code is committed to make it less time-consuming to fix. We plan to automate tests as much as possible to ensure better control of product quality. All tickets should be tested manually by the QA Team. Selected tests will be automated at the API level (by Cucumber) and the UI level (i.e. by Selenium).
The document describes the following issues: * Manual tests; * Manual testing standards: The UI style guide compatibility, translations and e.g. performance standards; * UI testing: Includes a list of types of supported devices/browsers prioritized for manual testing, and the strategy for testing the UI; * Responsibility; * Testing workflow: Describes the workflow for manual, automated testing and regression testing, and contains guidance on how to report bugs; * Regression testing; * Test environments and updating test data; * Performance tests; * Automated tests; * Tools: What tools are used for testing OpenLMIS.
## Manual Tests
Manual tests should: * Cover edge cases rather than happy paths:
Changing the column order in the requisition template should not affect existing requisitions (i.e. [change the order of the requisition columns](https://openlmis.atlassian.net/browse/OLMIS-1951));
Disabling/enabling requisition columns should not affect existing requisitions;
Blank mandatory fields;
Deactivation of different entities (programs, facilities etc.);
Running out of periods for the requisition workflow;
Verify email messages are sent (until there are appropriate automated patterns for this): * [Emails to the storeroom manager after requisition status changes](https://openlmis.atlassian.net/browse/OLMIS-2824);
Cover checking reports (until we have an automated pattern): * [Printing requisitions](https://openlmis.atlassian.net/browse/OLMIS-2271); * [Stock-Based requisition reports](https://openlmis.atlassian.net/browse/OLMIS-4826);
Not check whether a modal or a notification contains an exact text, but rather verify if it gives the user all important information and context: * “An error message implying the orderable was not found is displayed to the user”, instead of checking the exact message (The following error message is displayed to the user: “Orderable with code XYZ was not found”); * “A question asking about changing requisition status to Submitted”, instead of checking the exact message (The following error message is displayed to the user: “Are you sure you want to submit this R&R?”);
Not check any UI-specific details: * The order of the columns in a table; * Exact label names; * Exact placement of inputs; * Colors of elements if they are not significant (not notifications, buttons or validations).
## Manual Testing Standards
Testing Standards: * UI guidelines; * Internationalization; * Form entry and errors; * Loading performance; * Offline performance; * Role based access control (RBAC); * Exception scenarios.
### UI Testing
This section includes a list of types of supported devices/browsers prioritized for manual testing.
Past versions of OpenLMIS have officially supported Firefox. For OpenLMIS 3.0, we are prioritizing the support of Chrome because of global trends (e.g. see Mozambique Stats), its developer tools and auto-updating nature.
For the testing of OpenLMIS, our browser version priorities are: 1. Chrome: The newest version; 2. Firefox: The newest version.
The next most widely-used browser version is IE 11 but we don’t recommend testing and bug fixes specifically for any Internet Explorer compatibility in OpenLMIS.
The operating systems on which we should test are: 1. Windows 7 (by far the most-widely-used in Mozambique, Zambia, Benin and globally); 2. Windows 10.
Note: The QA team performs some tests with the use of Linux (Ubuntu) workstations. This is fine for API tests but Linux is not a priority environment for UI testing and for final testing of OpenLMIS. It’s important to test the UI using Chrome and Firefox on Windows 7 and Windows 10.
In other words, OpenLMIS developers and team members may be using Mac and Linux environments. It is fine to report bugs happening on the supported browsers (Chrome and Firefox) on those platforms, but we won’t invest QA time in extensive manual testing on Mac or Linux.
We asked different OpenLMIS implementations to share their Google analytics so that we can prioritize browser and device support in the future.
#### Strategy for Testing UI-specific Elements
The filter buttons should be checked by E2E tests (no need to test alignment in a separate ticket);
The sort buttons should be checked by E2E tests (no need to test alignment in a separate ticket);
We should include checking some component, like the filter button, in the E2E test for a specific screen, rather than create a specific manual test case for all occurrences;
Checking whether a given screen is accessible for a user with or without proper rights should be checked by E2E tests;
The situation of UI elements should not be tested;
Resizing input boxes should be checked by an E2E test;
Colors of rows in tables should not be tested;
Redirecting to the login form after token expiration should be checked by E2E tests;
The product grid/stockmanagement validations should be checked by E2E tests;
Toggles should be checked by an E2E test;
There is no need to have a test case for the background of the application;
The order of the items on the navigation bar should be checked by an E2E test;
Offline actions should be checked by E2E tests;
The filter button’s color should be checked by an E2E test;
The pagination component should not be checked separately because it is checked in other E2E tests (e.g. one concerning requisition submission);
The order of facilities within drop-downs has a unit test, so there is no need to check it manually;
The auto-save should be checked by an E2E test;
The table horizontal scrollbar should be tested manually;
The sticky columns should be tested manually;
The sticky headers should be tested manually;
The breadcrumbs should be tested manually;
The datepickers should be tested manually.
### Supported Devices
OpenLMIS 3.0 only officially supports desktop browsers with a pointer (mouse, trackpad, etc.). The UI will not necessarily support touch interfaces without a mouse pointer, such as iPad or other tablets. For now, we do not need to conduct tests or file bugs for tablets, smart watches or other devices.
### Screen Size
We suggest testing with the most popular screen sizes: 1. 1000 x 600 (this is a popular resolution for older desktop screen sizes; it is the 16:9 equivalent of the age-old 1024x768 size); 2. 1300 x 975 (this is a popular resolution for newer laptop or desktop screens).
The UI should work on screens within that range of sizes. The screen size can be simulated in any browser by changing the size of the browser window or with the use of the Chrome developer tools.
## Responsibility
Developers (all teams): * Writing unit tests for all code (we want test coverage to reach 80%-100%); * Writing integration and component tests as assigned in tickets or as a part of the acceptance criteria.
### Communication
QA meetings are scheduled to discuss testing-related topics, and the daily communication is held on the #QA slack channel for OpenLMIS. The meeting notes are maintained on the [QA Weekly meeting notes](https://openlmis.atlassian.net/wiki/spaces/OP/pages/114170699/QA+Weekly+meeting+notes) page.
## Testing Workflow within a Sprint
The testing process in the OpenLMIS project is divided into three areas: Manual testing, automated testing and regression testing. This section covers manual and regression testing performed with the use of Zephyr test cases and test cycles.
Step 1: Test Cases
When a new feature ticket that does not concern the API is assigned to a sprint, the QA lead or the tester has to create a test case and link it to the Jira ticket. This can happen in parallel to the development of the ticket. Test cases have to be created for each JIRA ticket that is assigned to a sprint and has to be tested manually; one mustn’t create test cases for API changes, as contract tests are used for their verification. It’s advised to create test cases before a sprint begins, but this can also be done once a sprint has started. Note that sometimes a given feature might be interrelated with the already-existing ones, which increases the risk of regression. In such situations, the developer working on the ticket should recommend the test cases that should be run in parallel to the testing of a given feature. If this proves impossible, they should inform the tester on the possible influence of the changes on other parts of the system.
Each new test case has to be reviewed (i.e. its content should be assessed; it should also be determined whether it concerns a feature that is vital to the system – if so, it has to be assigned the “CoreRegression” label), and thus its status should be “QA”. After the review, the test case’s status should be changed to “To Do”. Every 2 or 3 sprints, the test cases concerning the features that had been impacted by the most-recent changes should be reviewed, so as to ensure that they are still valid and that the test steps they include are not outdated.
In JIRA, click on “Create”. Select the project, in this case the project is “OpenLMIS General”. Then, select the “Issue Type” as Test. The “Summary”, “Components”, and “Description” can be copied from the ticket to keep consistency, or help in rewriting the test case in the next steps. Note that every valid test case has to have the “To Do” status and “Minor” priority. The test case’s name should be in accordance with the following convention: “Screen: Tested feature” (e.g. “Users: Searching for users”). After entering all data, click the “Create” button and a JIRA notification will pop up with the test case’s number.
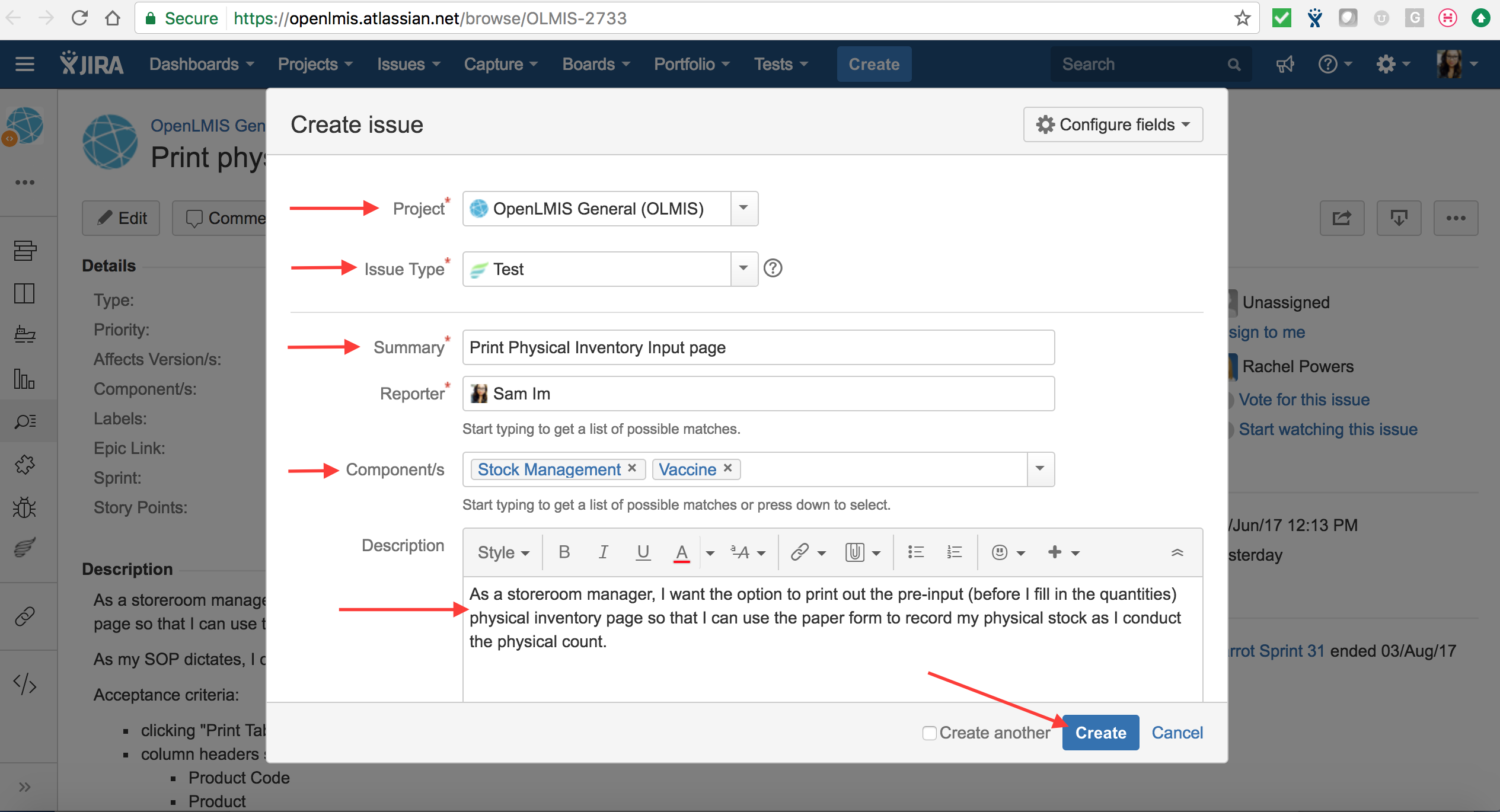
{kind=link}
Click the test case’s number, and it will bring you to the page enabling one to add the test steps and make required associations. Labels help when querying for test cases to add to regression test cycles. For the example below, a suggested label would be “Stock Management” or “Vaccines”. When the tested ticket concerns UI changes and contains a mock-up, the mock-up should be added as an attachment to the ticket with the test case.
The fix version/s is an association that organizes the test cases. This is used to report test case execution on the Test Metrics Dashboard. If the fix version is not known at the time of creating the test, select “Unscheduled”. When the JIRA ticket is assigned to a sprint, the test case must be updated with a correct fix version or it will not appear on the Test Metrics Dashboard. The test steps provide a step by step guide to any tester on how to complete proper validation of the JIRA ticket. The steps should explain in enough detail the actions to take, as well as the expected outcome of those steps.
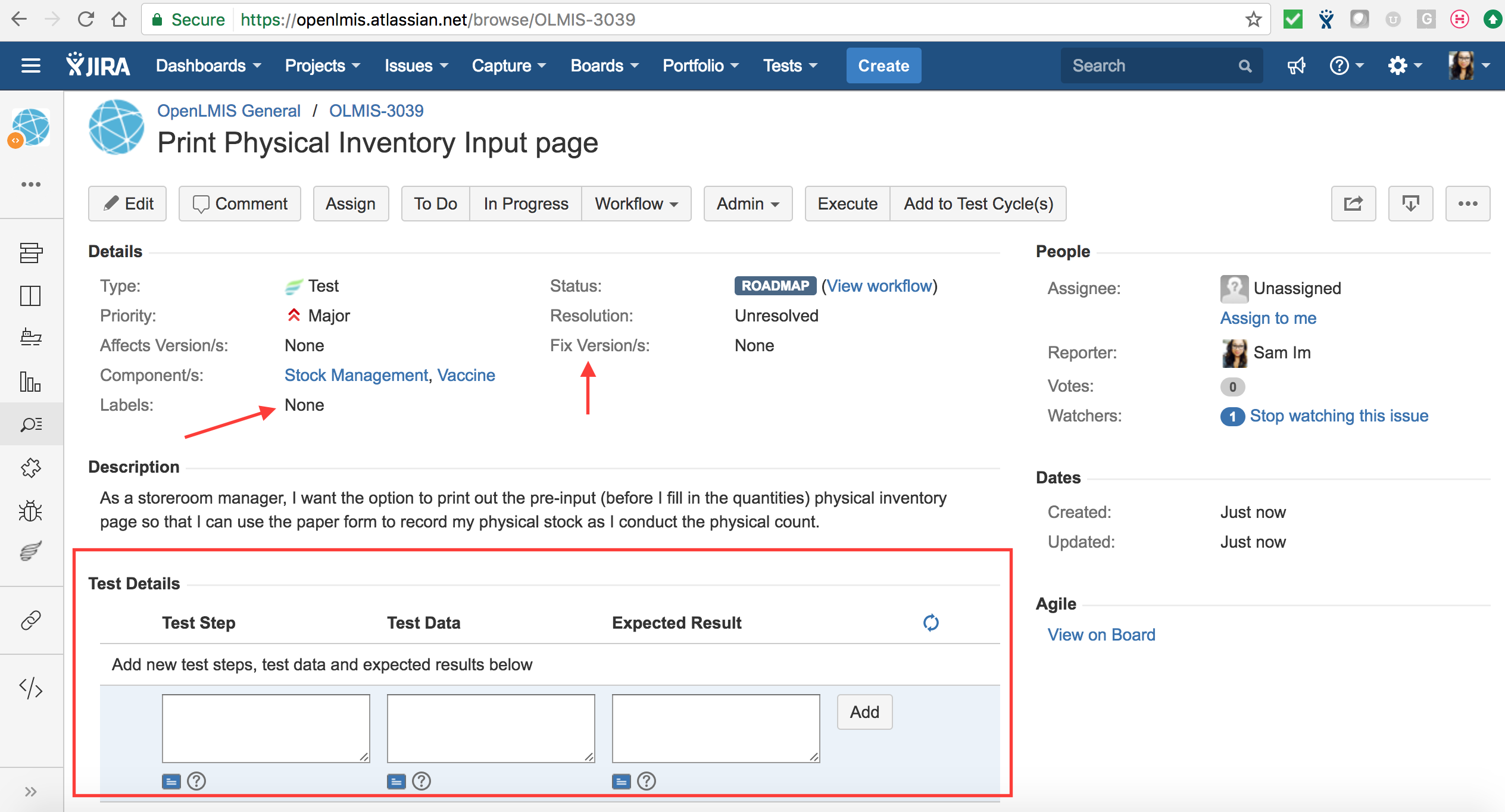
{kind=link}
Here is an example of some test steps:
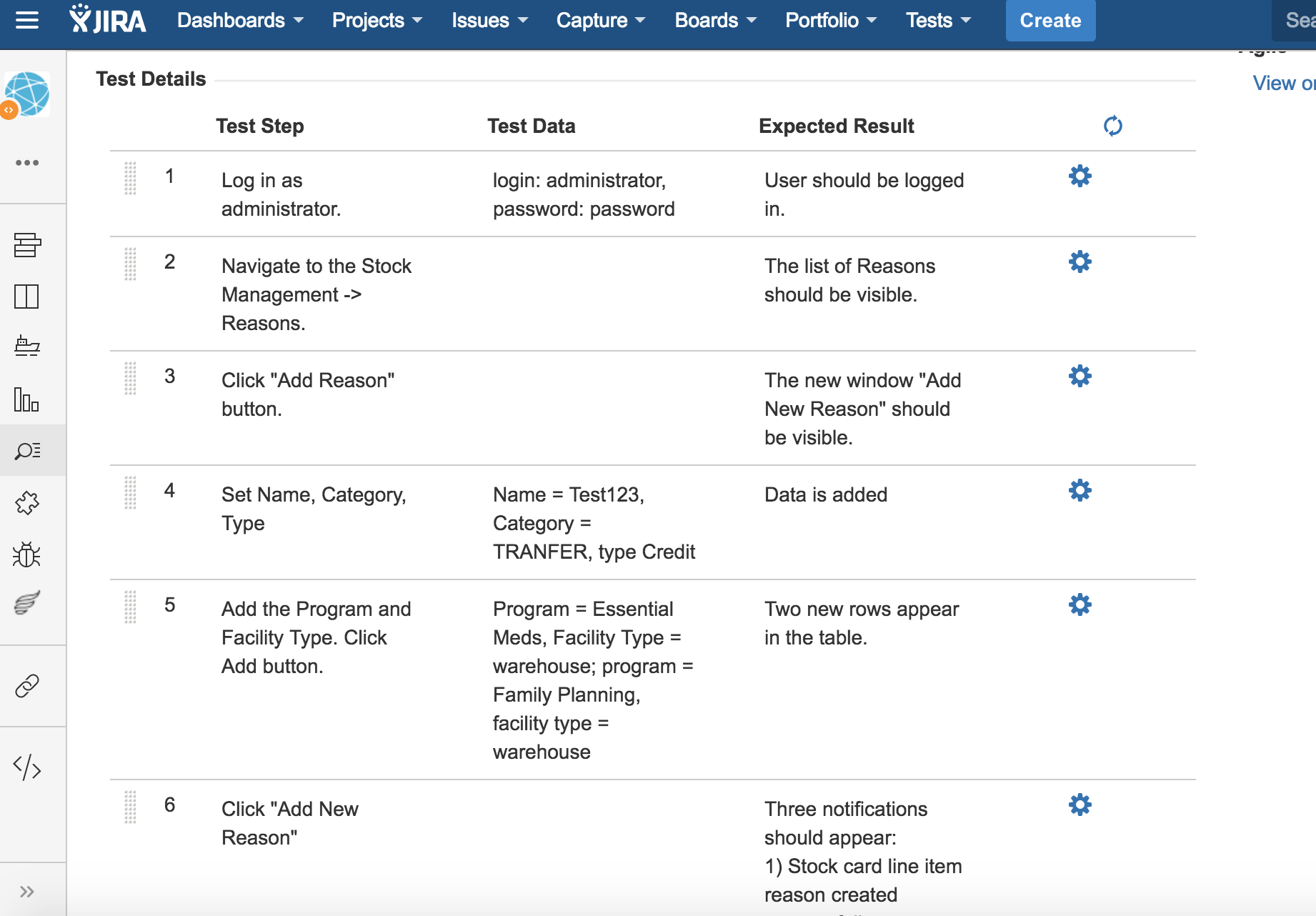
{kind=link}
Once the test case had been created, it needs to be associated with the JIRA ticket, as in the example below:
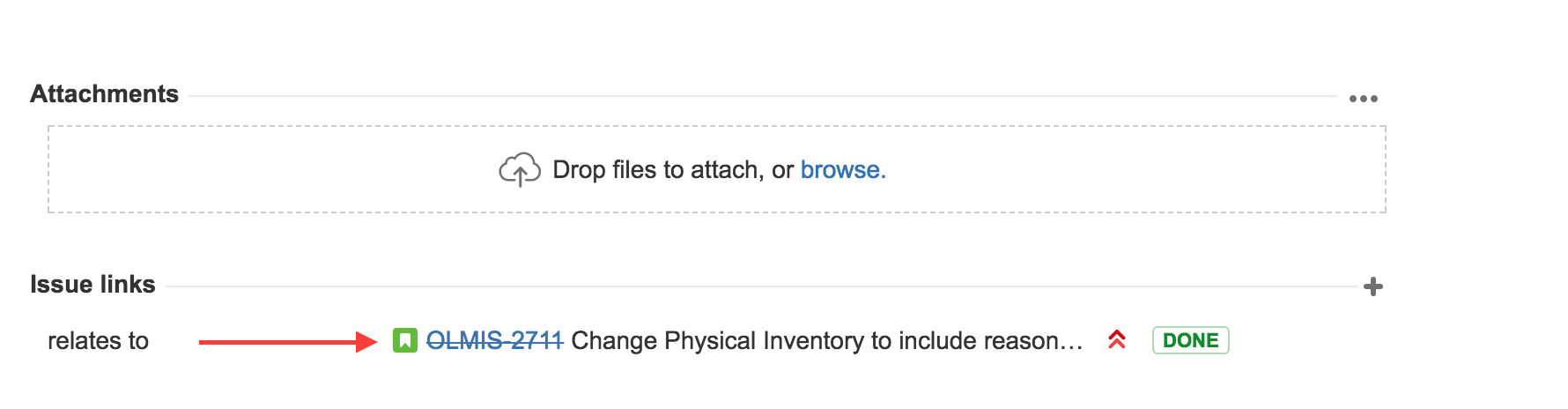
{kind=link}
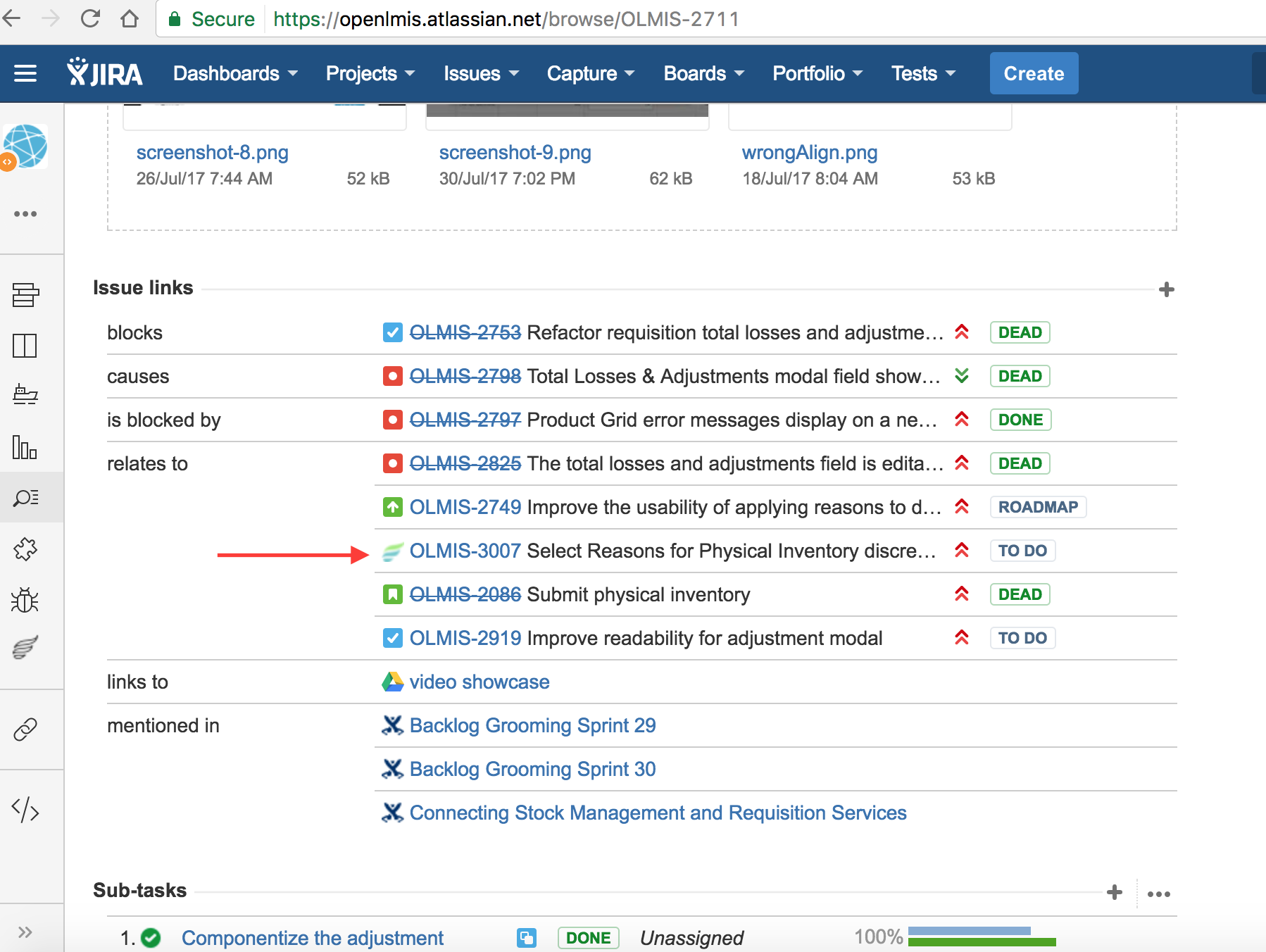
{kind=link}
## Test Case Best Practices
### Creating a Test Case for an Edge Case or Unhappy Path Scenario
One needs to add several types of details in the test case’s description. These include pre-conditions, i.e. conditions that need to be met before the test case can be executed (e.g. “At least one approved requisition needs to be created in the system”; “Logging into the application”), the acceptance criteria from the ticket, a description of the scenario/workflow (i.e. whether it is a happy-path one or an edge case, and what the workflow looks like; e.g. “User X authorizes a requisition, User Y rejects it, User X authorizes the requisition again”, etc.), and of the test case itself (e.g. “Tests whether it is possible to edit an approved requisition”; “Tests whether authorized users can approve requisitions”). In order to facilitate the execution of test cases concerning requisitions, one has to include the link to the [Requisition States and Workflow](https://openlmis.atlassian.net/wiki/spaces/OP/pages/113973375/Requisition+States+and+Workflow) diagram in the pre-conditions of such test cases.
If possible, one should not include too detailed data in the test case, e.g. user, facility or program names, as they may vary, depending on the implementation. So one should write e.g.: “Choose any program (e.g. Family Planning)”; “Knowing the credentials of any Stock Manager (e.g. srmanager2)”; “Knowing the credentials of any user authorized to approve requisitions (e.g. administrator)”, instead of: “Choose the Family Planning program” or “Knowing the password of srmanager2”. Information on user names, roles and rights is available [here](https://github.com/OpenLMIS/openlmis-referencedata/tree/master/src/main/resources/db/demo-data#roles-users-and-rights). Providing example test data can be especially helpful for users who are not very familiar with the system. One also has to remember to include the test data that are indispensable for the execution of the test case in the “Test Data” column for a given step. In principle, all data that are necessary to execute the test case should be included in it (e.g. mock-ups): One should write the test case in such a way that it’s not necessary to go to the tested ticket in order to test it.
Ideally, a test case should contain up to 40 steps at most. One can usually diminish their number by describing test actions in a more general manner, e.g.: “Approve the requisition”, instead of writing: “Go to Requisitions > Approve”, and describing the rest of the actions necessary for the achievement of the desired goal. Adding suitable pre-conditions, such as: “Initiating, submitting and authorizing a requisition”, instead of adding steps describing all of these actions in detail, also results in a shorter test case. Ideally, one should include all actions that are not verifying a given feature/bug fix in the pre-conditions. If it is not possible to keep the test case within the above-mentioned limit, one should consider creating more than one for a given ticket. Sometimes, splitting the testing of the ticket into more than one test case will prove impossible, though.
If this won’t result in a too long test case, one should include both the test steps describing positive testing (happy path scenario) and those concerning negative testing (edge case/unhappy path scenario) in one test case. A happy path scenario or positive testing consists in using a given feature in the default, most usual way, e.g. when there is a form with required and optional fields, one can first complete all of them or only the required ones and check what happens when one tries to submit it. An edge case or negative testing will consist, in this example, in checking what happens when trying to save the form when one or more of the required fields are blank. It is advisable to test the happy path first and then, the edge cases, as the happy path is the most likely scenario and will be most-frequently followed by users. Edge cases are the less usual and, frequently, not obvious scenarios, which are not likely to occur often but still need to be tested in order to prevent failures in the application from happening. They are taken into account because of software complexity (many possible variants of its utilization and thus situations that might occur), and because users, like all people, vary and can make use of the application in different ways.
If it proves impossible to contain all workflows in one test case, the happy path and the edge case(s) have to be described in separate ones, e.g. there should be one test case describing the testing of the happy path and one for each edge case. One also has to write separate test cases if the happy path and the edge case(s) contain contradictory steps or pre-conditions; e.g. the former concerns approving a newly-created requisition and the latter e.g. approving an already-existing old one, not meeting the currently-tested, new requirement.
Finally, one needs to remember that also the expected results have to be specific but not too specific: For instance, it is not recommended to provide exact text of messages and notifications. As an example of this, one shouldn’t write e.g.: “The <<Requisition has been deleted!>> notification should appear”. Instead, one should write: “The notification that the requisition had been deleted should appear”.
### Updating a Test Case for a Bug
When one has to test a bug, one needs to browse through the existing test cases to check whether one that covers the actions performed when testing the bug fix already exists. In virtually all cases, this will be the case. If it is so, one needs to update the test case if necessary and link it to the ticket with the bug. Writing new test cases for bugs is not recommended and has to be avoided. Some bugs are found during the execution of already-existing test cases. In such a situation, the test case will already be linked to the ticket with the bug. One then needs to review it, and if there is a need for it, update it. In most cases, this will not be necessary. Note that sometimes, the bug may in fact not be related to the test case during the execution of which it had been discovered, or it might occur by the end of a given test case, and the preceding steps might not be necessary in its reproduction. In both of these situations, one needs to find the test case that is most likely to cover the feature that the bug concerns and update it accordingly. One also has to keep in mind that test cases have to support and test the functionality, as well as provide a way to ensure that the bug had been fixed.
If the bug wasn’t found during the execution of any test case, one still needs to check whether there is one containing steps enabling one to reproduce the bug. In order to do so, one needs to go to “Tests > Search Tests” in the top menu on Jira. Then, one is able to browse through all test cases in the project. Since there might be many of them, it is advisable to use a filter. The first option is to enter word(s) that in one’s opinion might occur in the test case in the “Contains text” input field and press “Enter”. The second one is clicking on “More” and choosing the criteria. Those that are most likely to prove helpful are “Label” and “Component”. One can also use already-existing global filters, which can be found by choosing the “Manage filters” option from the main Jira menu. Then, it’ll be possible to search for and use the desired filter(s). They include e.g. “Administration tests” or “Stock Management test cases”, and might prove especially useful when searching for test cases.
### Exploratory Testing
When one is familiarizing oneself with the project or when one already knows the application but there are no tickets currently to test, one can perform exploratory testing. This kind of testing is not related to any ticket. It consists in testing the application without any previous plan, exploring it, in a way. It can be also considered as a form of informal regression testing, as frequently, bugs resulting from regression are found during it. While performing this kind of tests, it is advisable to be as creative as possible – to experiment with testing techniques and test steps, and not to follow the happy path but the edge cases, or to try to find the latter.
Exploratory testing in the UI will focus on testing edge cases and causing errors related to the following categories: Functional issues, UI to server failure, configuration issues, visual inconsistencies, and presentational issues.
Step 2: Test Cycles
Once the test case is written, it needs to be added to a test cycle. Click the “Add to Test Cycle(s)” button, and it will bring you to this screen:
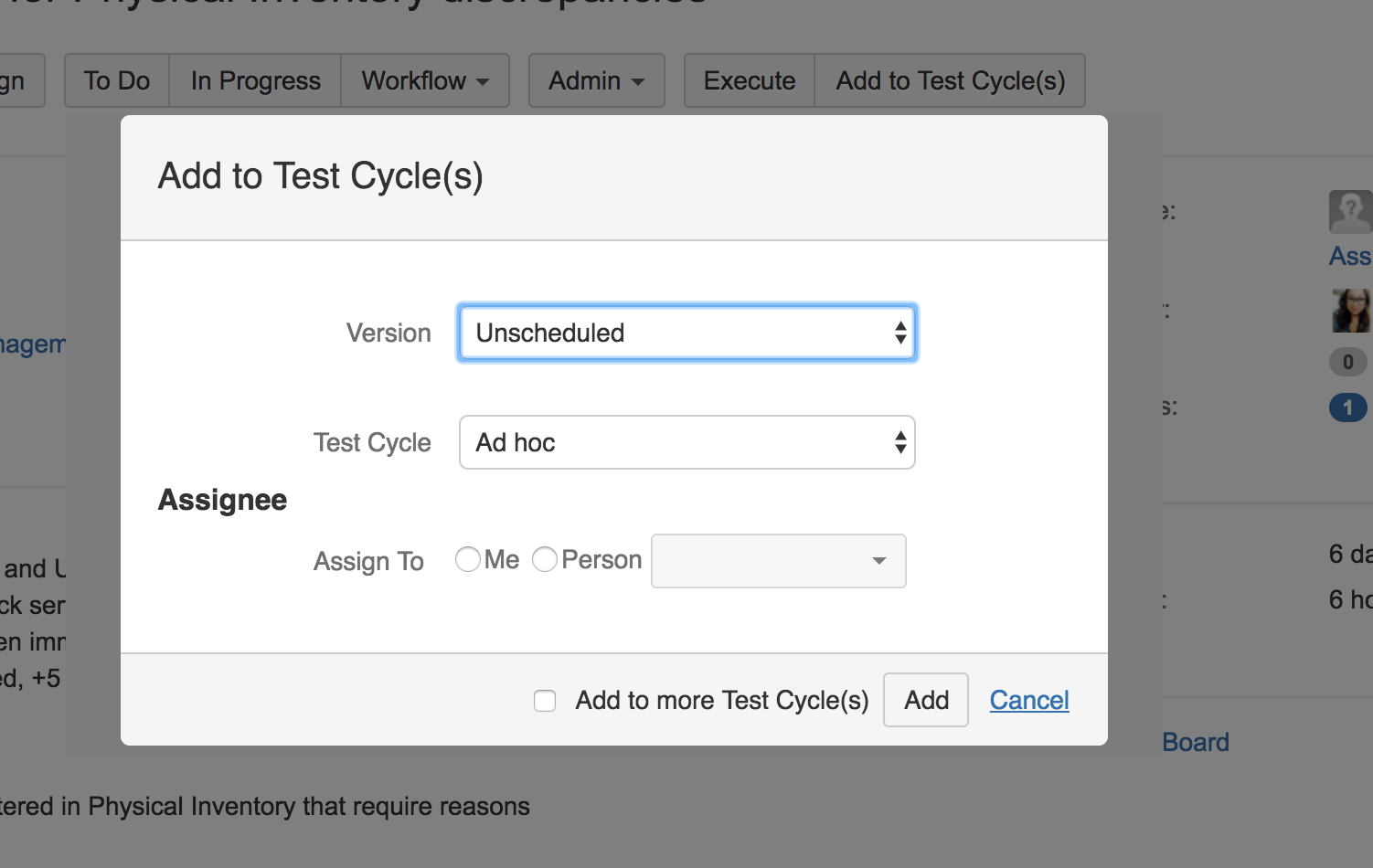
{kind=link}
The version should be the version that is associated with the JIRA ticket. The test cycle will be either the current sprint test cycle, or the current feature regression test cycle. If you are executing the test or know who will be executing it, you can assign it here.
Typically, the QA lead or someone designated will create the test cycles for each sprint and they will only need to be linked. If there are no test cycles to select, then these are the fields you must enter to create a new test cycle. The following are two examples of test cycles created for a sprint. The test cycles must have the version, name, description, and environment because they are used in queries for reporting and tracking test metrics.
e.g.
`
* Version - 3.2
* Name - Test Cycle for Sprint 31
* Description - Test Cycle for Sprint 31
* Environment - test.openlmis.org
* From (not required) - 2017-07-19
* To (not required) - 2017-08-02
`
Step 3: Execute Tests within a Test Cycle
Once test cases have been assigned to a test cycle, their execution is tracked in Zephyr. When a test is ready to be executed, open the test case and navigate to the bottom of the page where the “Test Execution” links are shown. Click the “E” button to begin execution.
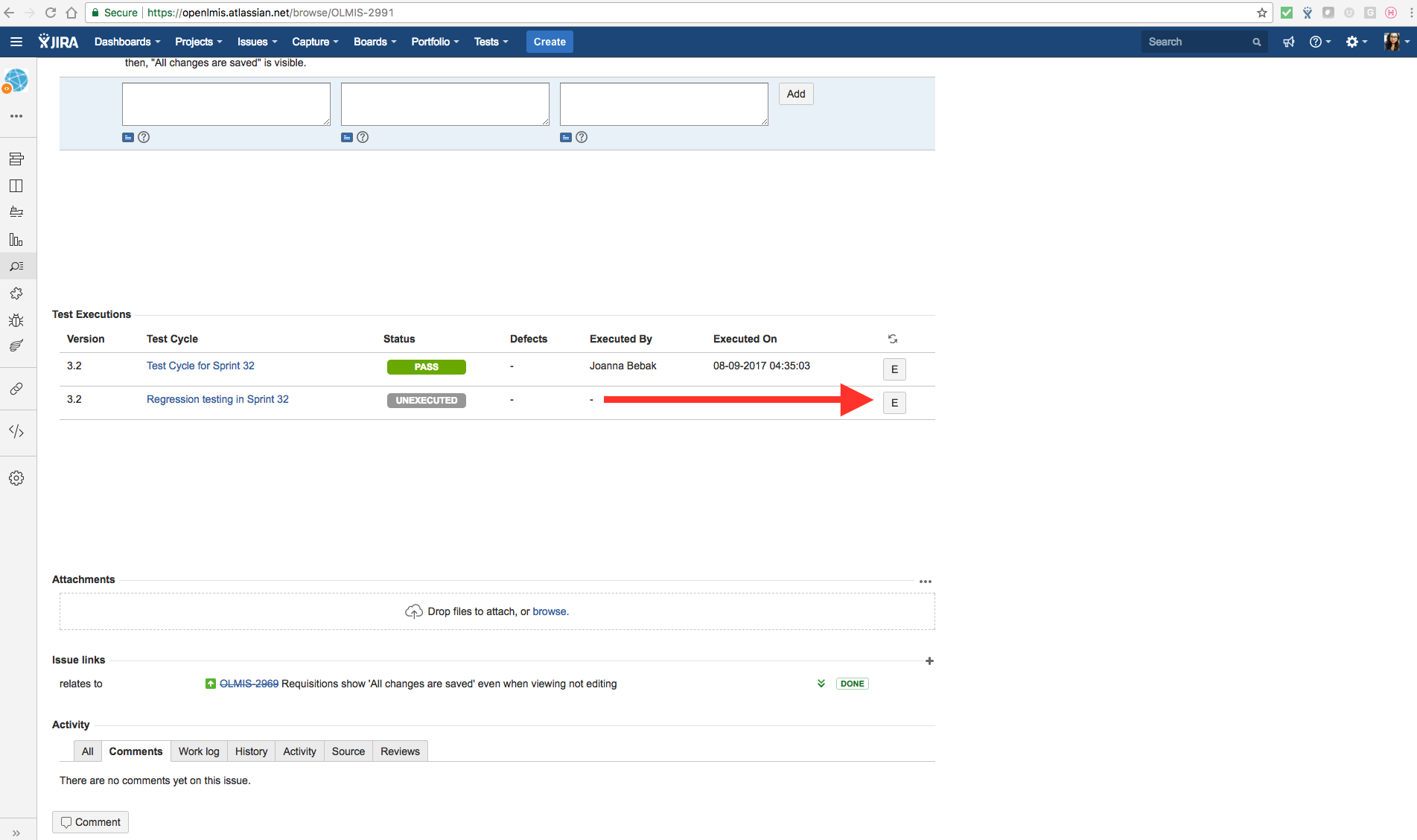
{kind=link}
The “Test Execution” page appears that details the test case and each test step. Select the “WIP” test execution status, which means that the test case is in progress. Zephyr will assign you as the person executing the test and automatically assign the start date and time. Assign the test execution to yourself, and you are ready to begin testing. Each step has “Status”, “Comment”, “Attachments” and “Defects” fields.
While completing each step, if the expected result matches the actual one, change the status to “Pass”. If the step execution does not match expectations, then the status is “Failed”. If for some reason the step cannot be executed, such as the system is down, then the status would be “Blocked”. Once the test is completed, its status can be updated to reflect whether it passed or failed, and the status of the test execution will be saved in the test case as shown on the above screenshot. This status also appears in the Test Metrics Dashboard.
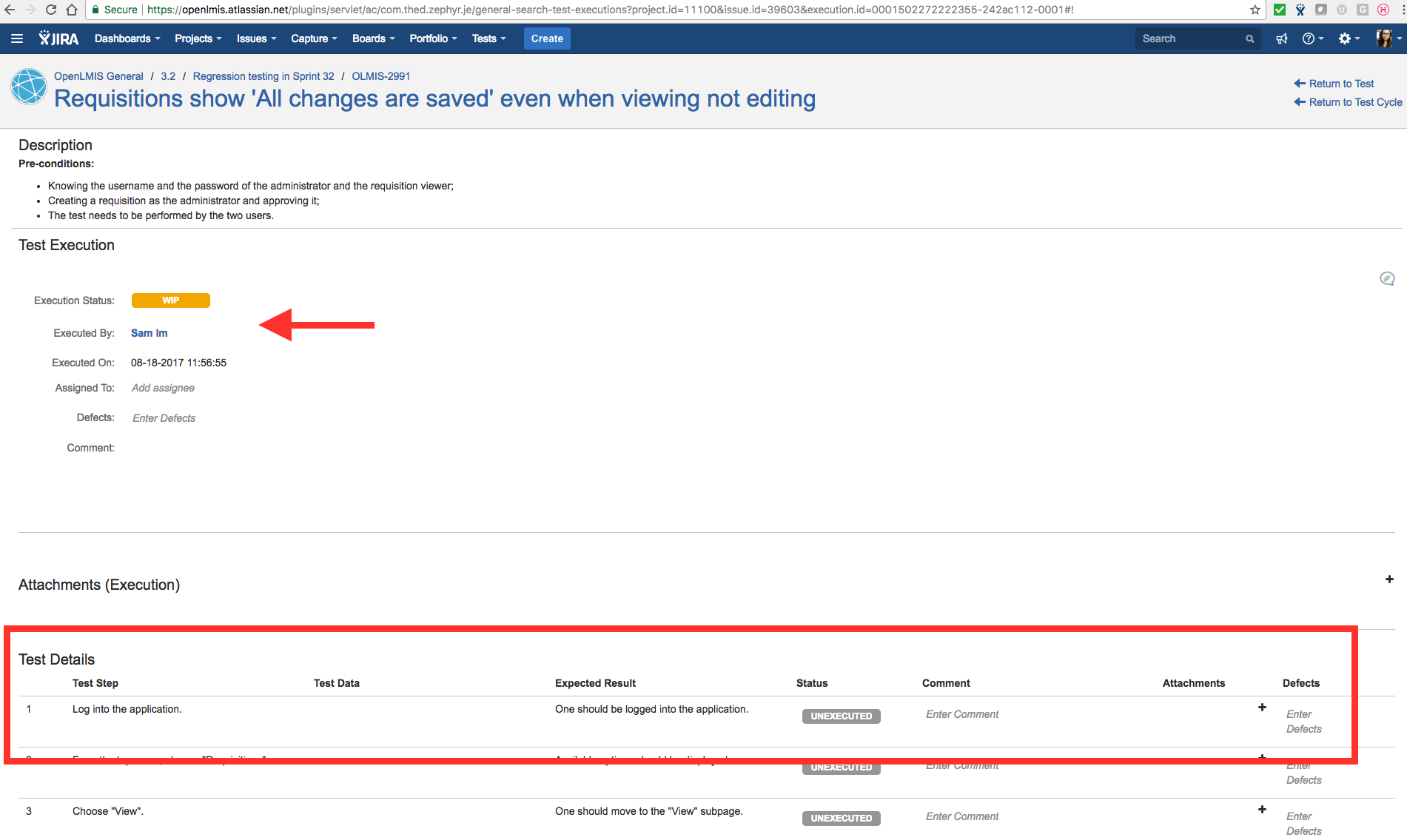
{kind=link}
Step 4: Enter Bugs
During testing, if a test step fails and there is a different result, or an error appears that is not expected, then a bug must be entered. Click on the “Defects” column and “Create New Issue”.
The issue type is “Bug”, and the summary, description, priority, environment, and the original linked JIRA ticket should all be added. The summary is a short description of the bug, while the description is a detailed step by step explanation of how to recreate the bug, and what the expected result is per the test case step. It’s helpful to have the test case open in a separate window so that you can copy those details if needed. The environment should be either test or UAT, and you should provide as much detail about the environment that would help the developer when reproducing the bug, such as in which browser you tested.
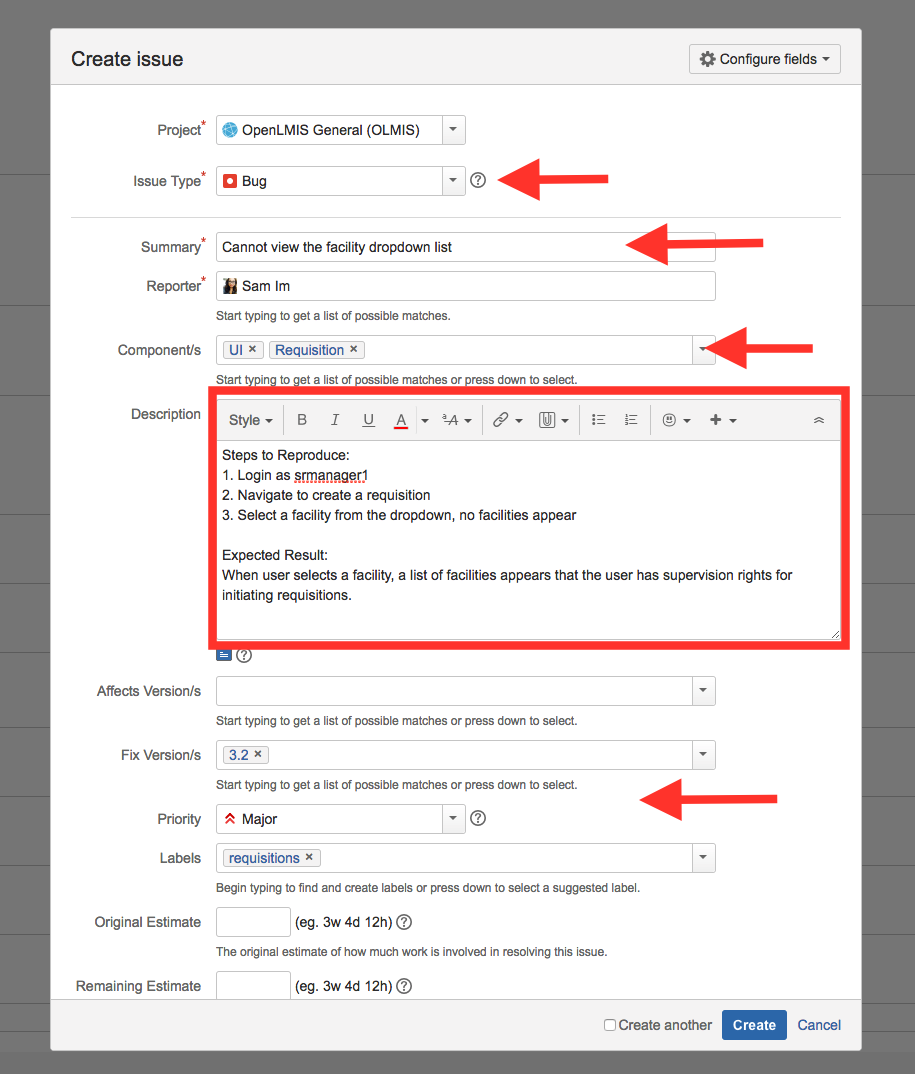
{kind=link}
The new bug should be linked to the JIRA ticket that is linked to the test case.
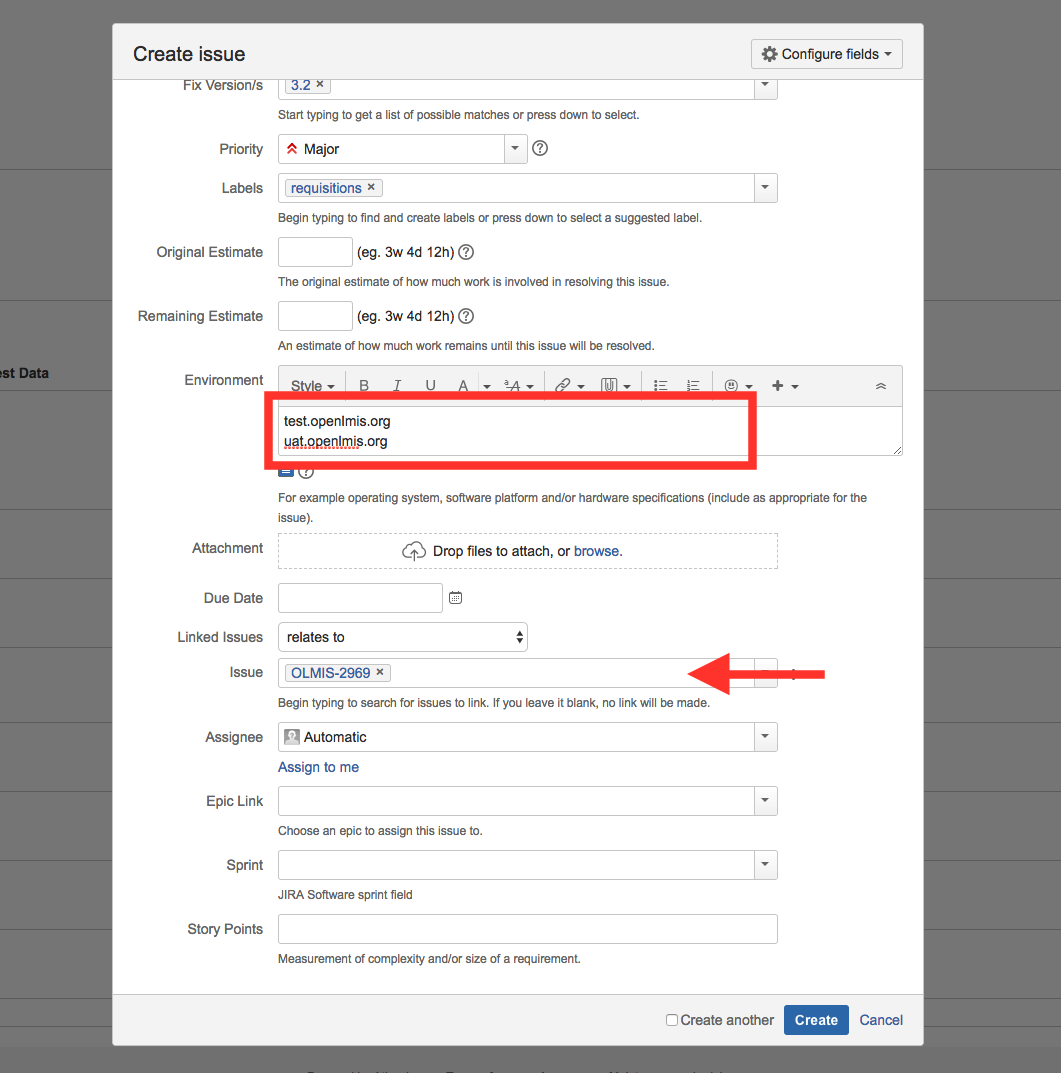
{kind=link}
When a bug is created, it will automatically get sent to the “Roadmap” status. It should stay in this status until it has been triaged and reproduced – only then its status can be changed to “To Do” and when it happens, the bug becomes visible in the product backlog. In summary, each of these steps completes the QA workflow process for a sprint.
Test Coverage: For each sprint’s test cycle, the QA lead must assign appropriate test cases so that they can be executed during the sprint. These test cases will be selected based on the tickets assigned to the sprint after the Sprint Planning. The QA lead must determine if test cases are missing for the tickets assigned to the sprint, and create those test cases to ensure complete test coverage. New features require new test cases, while bugs or regression test cycles may rerun existing ones.
### Sprint Grooming and Planning Workflow
The tester is responsible for adding test cases to support all testing within the sprint. At the end of each sprint in which regression testing was performed, the QA lead is expected to showcase the results. This should include: Showing the test cycle, the execution metrics, # of added test cases and the final status of bugs found in the sprint (bug tracking).
### Bug Tracking
It is important to track the bugs introduced during each sprint. This process helps to identify test scenarios that may need more attention or business process clarification. Bug tracking also helps to identify delays in ticket completion. * When a test case fails, a bug must be created and linked to the ticket. This bug has to be resolved before the ticket can be marked as done; * The same test case associated with the sprint’s test cycle should be run; * If a bug is created for the test case, it has to be resolved before the test is executed again in the sprint cycle.
### Bug Triage During the Sprint
The bug triage meeting is held twice every sprint, i.e. once a week. Before the meeting, bugs with the “Roadmap” status are attempted to be reproduced and if they still occur, their status is changed to “To Do”. If not, they are moved to “Dead”. During the meeting, the bugs reported are analyzed in terms of their significance to the project, their final priority is set and the acceptance criteria are updated.
### Manual Testing Workflow
When the developer finishes implementing the ticket, he/she should change its status from “In Progress” to “QA”. The tester should then check whether all acceptance criteria are correct and up-to-date.
The main manual testing workflow consist of the following steps: 1. The tester starts testing when the ticket is moved to the “QA” column on the Jira sprint board, or when the ticket’s status changes to “QA”. There is no automatic notification for this until the ticket is assigned, so the tester has to check manually or the developer has to notify the tester. 2. The tester deploys changes to the test environment (uat.openlmis.org). 3. The tester creates a test case, or executes an existing one that is linked to the ticket. The tester should test all acceptance criteria in the ticket. The test case has to be associated with the current sprint test cycle. 4. If bugs are found, the tester should change the ticket’s status to “In Progress” and assign it to a proper developer.
When a bug is created, it has to be linked to the ticket;
The tester notifies the developer that the ticket was moved back to “In Progress”.
When everything works properly, the tester should change the status to “Done” and assign the ticket to the developer who worked on it.
During the testing process, the tester should write comments in the ticket about the tested features and add the screenshots depicting the noticed issues.
### Workflow Between the QA Teams
To improve the testing process, testers should help each other: * If one of the team members doesn’t have anything to do in their own team, they should assist other teams in testing; * If any tester needs help with testing, they can report it on the QA Slack channel.
### Ticket Workflow and Prioritization
In the OpenLMIS project, tickets may have the following statuses: * “Roadmap”: Tickets intended for implementation but not ready for it; e.g. for which the acceptance criteria or other details still need to be defined; * “To Do”: Tickets ready for implementation; * “In Progress”: Tickets currently being implemented or returned to the developer in order to fix bugs; * “In Review”: Tickets in code review; * “QA”: Tickets which should be tested; * “Done”: Tickets which work correctly and are finished.
Ticket priorities are described in [“Prioritizing Bugs”](https://openlmis.readthedocs.io/en/latest/contribute/contributionGuide.html#prioritizing-bugs).
It is very important to start testing tickets with the “Blocker” and “Critical” priority first. When the tester is in the middle of the testing process for a task with lower priority (i.e. “Major”, “Minor” or “Trivial”), and a task with higher priority (i.e. “Blocker” or “Critical”) returns with changes to the “QA” column, the tester should complete testing the task with lower priority as soon as possible and begin testing the task with higher priority.
Additionally, tickets on the [Sprint dashboard]( https://openlmis.atlassian.net/secure/RapidBoard.jspa?rapidView=46 ) in the “QA” column should be prioritized. Tickets with high priority (i.e. “Blocker” or “Critical”) should be located at the top of the “QA” column. Every morning, the QA lead should set the tasks in the “QA” column in correct order.
### Regression Testing Workflow
Regression testing for OpenLMIS is organized by each of the features (Requisition, Stock Management, Fulfillment, CCE, Administration, etc.) and the test cases are labeled with the feature’s name in order to facilitate the planning of regression testing cycles. The tests are managed via the creation of a regression test cycle and assigning it to the sprint. The test cases that are labeled with the feature should include workflow scenarios for the feature, as well as any edge cases that have been identified as required for regression testing.
When creating the regression test cycle, the QA lead will search for test cases with the feature label and assign all of them to the regression test cycle.
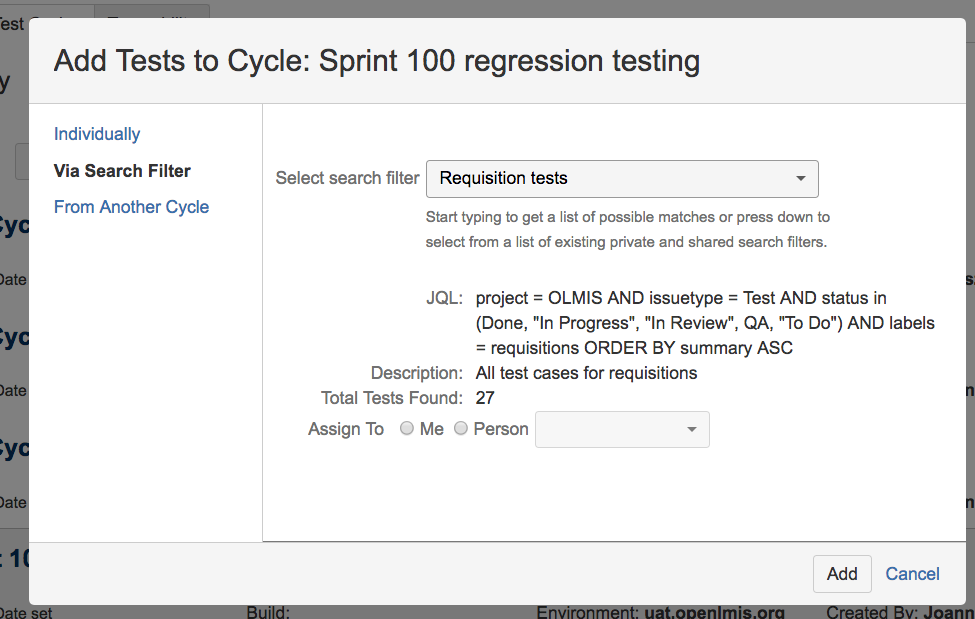
{kind=link}
Regular manual regression should be executed every second sprint (i.e. once a month). This kind of regression testing is focused on specific services, it doesn’t entail testing the entire system. Testers decide what services the regular, focused regression testing is to cover during the QA meetings, and their decision is based on the most-recent changes in the system. For instance, if many changes had been recently introduced in requisitions, the regression testing will consist in the execution of all test cases concerning the requisition service.
Big, full manual regression, consisting in manual tests of the whole system and the execution of all valid test cases, is held one or two weeks before the Release Candidate process. The latter is further described in the [“Versioning and Releasing”](http://docs.openlmis.org/en/latest/conventions/versioningReleasing.html#release-process) document.
When bugs are found during regression testing, they are labeled with the “Regression” label. The regression-testing-related bugs are usually considered either “Critical” or “Blocker” ones that must be resolved in the current or in the next sprint. These bugs are also reviewed on the weekly bug triage meeting for completeness, and in order to ensure communication of any concerns to stakeholders.
### Workflow for Blocked Tickets
Sometimes during testing, one might come across blocked tickets. This is a situation in which, because of external faults (not related to the content of the task), the tester cannot test a particular ticket. In such a case, one has to change the ticket’s status to “In Progress” and assign it to the developer who implemented the ticket. It is important to describe the problem accurately in a comment.
## Test Environments
Final tests of all features should be conducted on the [UAT server](https://uat.openlmis.org/). Some testing may also happen on the [test server](https://test.openlmis.org/), in case the UAT server is temporarily unavailable. The UAT server’s rebuilding is triggered manually. In order to rebuild it, and thus perform the test on the latest changes, one has to log into [Jenkins](http://build.openlmis.org/) and schedule a build of the OpenLMIS-3.x-deploy-to-uat job. One needs to do it when no other jobs are in the build queue, so to to ensure that the server contains the latest changes. After the build is successful, one has to wait for several minutes and then, it is possible to start testing. The test server always contains the latest changes but its use is not normally recommended, as it is very frequently rebuilt (after the rebuilding, all data entered during testing are erased) because it is used for development work. In order to be sure that the server contains the most-recent changes, one has to log into the application and look at the upper-right corner, where information on when the software had last been updated is visible. If only the e.g. “Software last updated on XX/XX/XXXX” text is visible, the software is up to date. As soon as it becomes outdated, information that there are updates available appears next to the text concerning the date of the last update.
## Updating Test Data
Before big regression testing, the tester has to update the test users and scenarios to support each of the features that are part of the big regression testing. It is also important to note that several test cases entail changing the permissions of demo-data users. Before executing such a test case, one needs to inform others on the #qa Slack channel that one is going to change these permissions. Having executed the test case, one has to restore the user’s permissions to the default ones manually or by scheduling a re-deploy to UAT. In both cases, one has to inform users on #qa that one is changing the user’s permissions back to normal. In general, one should avoid changing the permissions of demo-data users if it can be avoided. Instead, one can create a new user and assign suitable rights to them.
## Translation Testing
While OpenLMIS 3.0 supports a robust multi-lingual tool set, English is the only language officially provided with the product itself. The translation tools will allow subsequent implementations to easily provide a translation to Portuguese, French, Spanish, etc. Test activities should verify that message keys are being used everywhere on the UI and in error messages so that every string can be translated, with no hard coding. The v3 UI is so similar to v2 that testers could also apply the Portuguese translation strings from v2 to confirm that translations apply everywhere in v3.
## Performance Testing
Apart from the usual manual testing, each ticket with the “NeedsPerformanceCheck” label has to undergo performance testing. The instructions on how to perform this kind of tests are available in the “How do I record more test runs?” and “Release testing for 3.3” sections on the [“Performance Metrics”](https://openlmis.atlassian.net/wiki/spaces/OP/pages/116949318/Performance+Metrics) page, only one has to use the UAT server and the credentials of users available at that instance. One has to pay attention especially to the CPU throttling (6x slowdown) and Network (Slow 3G) settings, as they are vital in this kind of testing and render the results of different users comparable.
## Types of Automated Tests The following test categories have been identified for use in OpenLMIS. As illustrated in this [slide deck](http://martinfowler.com/articles/microservice-testing/), we expect the effort/number of tests in each category to reflect the [test pyramid](http://martinfowler.com/articles/microservice-testing/#conclusion-test-pyramid):
[Unit](#unit);
[Integration](#integration);
[Component](#component);
[Contract](#contract);
[End-to-End](#e2e).
### Unit Tests <a name=”unit”></a>
Who: Written by the code’s author during the implementation.
What: The smallest unit (e.g. one piece of a model’s behavior, a function, etc.).
When: At build time, should be fast and targeted, it should be possible to run only a part of the test suite.
Where: Reside inside a service, next to the unit under test. Generally able to access package-private scope.
Why: To test fundamental pieces/functionality, help guide and document design and refactors, protect against regression.
#### Unit Test Examples
__Every single test should be independent and isolated. The unit test shouldn’t depend on another unit test.__
DO NOT: ```java List<Item> list = new ArrayList<>();
@Test public void shouldContainOneElementWhenFirstElementisAdded() {
Item item = new Item(); list.add(item); assertEquals(1, list.size());
}
@Test public void shouldContainTwoElementsWhenNextElementIsAdded() {
Item item = new Item(); list.add(item); assertEquals(2, list.size());
__One behavior should be tested in just one unit test.__
DO NOT: ```java @Test public void shouldNotBeAdultAndShouldNotBeAbleToRunForPresidentWhenAgeBelow18() {
int age = 17; boolean isAdult = ageService.isAdult(age); assertFalse(isAdult);
boolean isAbleToRunForPresident = electionsService.isAbleToRunForPresident(age) assertFalse(isAbleToRunForPresident);
DO: ```java @Test public void shouldNotBeAdultWhenAgeBelow18() {
int age = 17; boolean isAdult = ageService.isAdult(age); assertFalse(isAdult);
}
@Test public void shouldNotBeAbleToRunForPresidentWhenAgeBelow18() {
int age = 17; boolean isAbleToRunForPresident = electionsService.isAbleToRunForPresident(age) assertFalse(isAbleToRunForPresident);
__Every unit test should contain at least one assertion.__
DO NOT: ```java @Test public void shouldNotBeAdultWhenAgeBelow18() {
int age = 17; boolean isAdult = ageService.isAdult(age);
DO: ```java @Test public void shouldNotBeAdultWhenAgeBelow18() {
int age = 17; boolean isAdult = ageService.isAdult(age); assertFalse(isAdult);
__Don’t make unnecessary assertions. Don’t assert mocked behavior, avoid assertions that check the exact same thing as another unit test.__
DO NOT:
__The unit test has to be independent from external resources (i.e. don’t connect with databases or servers).__
DO NOT:
- ```java
@Test public void shouldNotBeAdultWhenAgeBelow18() {
String uri = String.format(”http://127.0.0.1:8080/age/”, HOST, PORT); HttpPost httpPost = new HttpPost(uri); HttpResponse response = getHttpClient().execute(httpPost); assertEquals(HttpStatus.ORDINAL_200_OK, response.getStatusLine().getStatusCode());
__The unit test shouldn’t test Spring contexts. Integration tests are better for this purpose.__
DO NOT:
- ```java
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(locations = {“/services-test-config.xml”}) public class MyServiceTest implements ApplicationContextAware {
@Autowired MyService service; …
@Override public void setApplicationContext(ApplicationContext context) throws BeansException {
// something with the context here
}
__The test method’s name should clearly indicate what is being tested and what is the expected output and condition. The “should - when” pattern should be used in the name.__
DO: ```java @Test public void shouldNotBeAdultWhenAgeBelow18() {
…
@Test public void firstTest() {
…
}
@Test public void testIsNotAdult() {
…
__The unit test should be repeatable: Each run should yield the same result.__
DO NOT: ```java @Test public void shouldNotBeAdultWhenAgeBelow18() {
int age = randomGenerator.nextInt(100); boolean isAdult = ageService.isAdult(age); assertFalse(isAdult);
__You should remember about initializing and cleaning each global state between test runs.__
DO: ```java @Mock private AgeService ageService; private age;
@Before public void init() {
age = 18; when(ageService.isAdult(age)).thenReturn(true);
}
@Test public void shouldNotBeAdultWhenAgeBelow18() {
boolean isAdult = ageService.isAdult(age); assertTrue(isAdult);
__The test should execute fast. When we have hundreds of tests, we don’t want to wait several minutes until all tests pass.__
DO NOT:
### Integration Tests <a name=”integration”></a>
Who: The code’s author during the implementation.
What: Test basic operation of the service to persistent storage or a service to another service. When another service is required, a test double should be used, not the actual service.
When: As explicitly asked for, these tests are typically slower and therefore need to be kept separate from the build in order not to slow the development down. Are run on the CI on every change.
Where: Reside inside a service, separated from other types of tests/code.
Why: Ensure that basic pathways to a service’s external run-time dependencies work, e.g. that a db schema supports the ORM, or that a non-responsive service call is gracefully handled.
As far as testing controllers is concerned, tests are divided into unit and integration tests. Controller unit tests test the logic in the controller, and integration tests test serialization/deserialization (and therefore do not need to test all code paths). In both cases, the underlying services and repositories are mocked.
### Component Tests <a name=”component”></a>
Who: The code’s author during the implementation.
What: Test more complex operations in the service. When another service is required, a test double should be used, not the actual service.
When: As explicitly asked for, these tests are typically slower and therefore need to be kept separate from the build to not slow the development down. Will be run on the CI on every change.
Where: Reside inside a service, separated from other types of tests/code.
Why: Test whether interactions between components in the service work as expected.
These are not integration tests, which strictly test the integration between the service and an external dependency. These test whether the interactions between the components in the service are correct. While integration tests verify only whether the basic pathways work, component tests verify whether, based on the input, the output matches expectations.
They are not contract tests, which are more oriented towards business requirements, but are more technical in nature. The contract tests will make certain assumptions about components, and these tests make sure those assumptions are tested.
### Contract Tests <a name=”contract”></a>
Who: The code’s author during the implementation, with the BA/QA’s input.
What: Enforce contracts between and to services.
When: Run on the CI.
Where: Reside inside a separate repository: openlmis-contract-tests.
Why: Test multiple services working together, testing contracts that the service both provides, as well as the requirements a dependency has.
Ideally, a single scenario checks a single endpoint. In specific cases, like the requisition workflow, when it’s impossible to check something without using other endpoints, it can be omitted.
The main difference between contract and integration tests: In contract tests, all services under test are real, meaning that they will be processing requests and sending responses. Test doubles, mocking, stubbing should not be part of contract tests.
Contract tests should follow the convention below: * The scenario should be like _<user_name> should be able to <action_description>_; * The feature’s name should consist of infinitive + noun in plural, e.g. _Creating facility type approved products_ or testing the FTAP creating screen/endpoint.
``` @FacilityTypeApprovedProductTests Feature: Creating facility type approved products
- Scenario: Administrator should be able to create FTAP
Given I have logged in as admin
When I try to create a FTAP: | orderable.id | program.id | facilityType.id | maxPeriodsOfStock | minPeriodsOfStock | emergencyOrderPoint | | 2400e410-b8dd-4954-b1c0-80d8a8e785fc | dce17f2e-af3e-40ad-8e00-3496adef44c3 | ac1d268b-ce10-455f-bf87-9c667da8f060 | 3 | 1 | 1 | Then I should get response with created FTAP’s id And I logout
Refer to [this doc](https://github.com/OpenLMIS/openlmis-contract-tests/blob/master/README.md) for examples on how to write contract tests.
Contract tests should: * Cover the contract between services:
Reasons from Stock Management provided for the requisition service: [Stock reasons contract tests](https://github.com/OpenLMIS/openlmis-contract-tests/blob/master/src/cucumber/resources/org/openlmis/contract_tests/stockmanagement_tests/StockReasonsTests.feature);
Converting requisitions to orders: [Fulfillment contract tests](https://github.com/OpenLMIS/openlmis-contract-tests/blob/master/src/cucumber/resources/org/openlmis/contract_tests/fulfillment_tests/FulfillmentTests.feature);
The dependencies between the user resources in different services: [Users contract tests](https://github.com/OpenLMIS/openlmis-contract-tests/blob/master/src/cucumber/resources/org/openlmis/contract_tests/referencedata_tests/UserTests.feature); [Contact details contract tests](https://github.com/OpenLMIS/openlmis-contract-tests/blob/master/src/cucumber/resources/org/openlmis/contract_tests/notification_tests/VerificationTests.feature);
The information provided to the UI;
Cover checking the email templates (but appropriate patterns are required for email verification, there are no tests present at the moment);
Cover checking file upload: * [ISA values upload](https://github.com/OpenLMIS/openlmis-contract-tests/blob/master/src/cucumber/resources/org/openlmis/contract_tests/referencedata_tests/IdealStockAmountTests.feature#L7).
### End-to-End Tests <a name=”e2e”></a>
Who: Tester/developer with input from the BA.
What: Typical/core business scenarios.
When: Run on the CI.
Where: Reside in separate repository.
Why: Ensure that all the pieces work together to carry-out a business scenario. Help ensure that end-users can achieve their goals.
A single feature should cover only one (related) UI screen.
End-to-end tests should follow the convention below: * The scenario should be like _<user_name> should be able to <action_description>_; * The feature’s name should consist of infinitive + noun in plural, e.g. _Adding reasons_ for testing the reason adding screen/endpoint.
``` Feature: Adding reasons
- Background:
Given I have logged with username “administrator” and password “password” Given I have navigated to the reason list page
- Scenario: Administrator should be able to add new reason
When I click on the “Add Reason” button Then I should be brought to the reason creation page
When I select “Family Planning” from the “Program” list And I select “Warehouse” from the “Facility Type” list And I click on the “Add” button Then I should see assignment for “Family Planning” program and “Warehouse” facility type
When I enter “Functional Test Reason” as “Name” And I select “Transfer” from the “Category” list And I select “Debit” as “Type” And I enter “adjustment” as “Tags” And I click on the “Add New Reason” button Then I should see a successful notification saying “Reason saved successfully” And I should see a reason with “Functional Test Reason” name, “Transfer” category and “Debit” type inside the table
E2E tests should: * Cover workflow happy paths:
Basic requisition workflow;
Basic order workflow;
Sending stock events.
Not cover edge cases which require multiple steps from different microservices: * Sending data from the requisition to the stockmanagement service.
Cover checking functionalities dependent on user rights: * The presence of elements on the navigation bar; * The visibility of action buttons; * Editable fields in forms.
Check UI differences dependent on choosing specific options: * How the requisition product grid screen behaves for emergency and regular requisitions; * Differences between stock-based and non-stock-based requisitions; * Differences between working with home and supervised facility.
Not check any specific UI details: * The order of columns in tables; * Exact label names; * Exact placement of inputs; * Colors of elements if they are not significant.
## Testing Services Dependent on External APIs OpenLMIS uses WireMock to mock web services. An example integration test can be found [here](https://github.com/OpenLMIS/openlmis-example/blob/master/src/test/java/org/openlmis/example/WeatherServiceTest.java).
The stub mappings which are served by the WireMock’s HTTP server are available under _src/test/resources/mappings_ and _src/test/resources/files_. For instructions on how to create them, please refer to http://wiremock.org/record-playback.html.
## Testing Tools
Cucumber and IntelliJ: For contract tests;
Browsers: Chrome (the latest version) and Firefox (the latest version);
REST clients: Postman, API Console and REST Client;
JIRA: Issue-, task- and bug tracking;
Zephyr: Test case and test cycle creation;
Confluence: Project documentation, e.g. various guides and meeting notes;
Reference Distribution;
Docker 1.11+;
Docker Compose 1.6+;
Spring-boot-starter-test: * Spring Boot Test; * JUnit; * Mockito; * Hamcrest;
[WireMock](http://wiremock.org);
[REST Assured](http://rest-assured.io);
[raml-tester](https://github.com/nidi3/raml-tester).